10 September 2012
codeq
Backstory
Programmer Sally: "
So, what are you going to do today Bob?"Programmer Bob: "
I'm not happy with the file baz.clj residing in my/ns. So I'm going to go to line 96 and change 2 to 42. I've been thinking about deleting line 124. If I have time, I'm also going to insert some text I've been working on at line 64."Programmer Sally:
(what's wrong with Bob?)Short Story
codeq ( 'co-deck') is a little application that imports your Git repositories into a
Datomic database, then performs language-aware analysis on them, extending the Git model down from the file to the code quantum (
codeq) level, and up across repos. By doing so,
codeq allows you to:
- Track change at the program unit level (e.g. function and method definitions)
- Query your programs and libraries declaratively, with the same cognitive units and names you use while programming
- Query across repos
The resulting database is highly programmable, and can serve as infrastructure for editors, IDEs, code browsing, analysis and documentation tools.
codeq is open source (EPL), and
on github. It works with
Datomic Free.
Long Story
We love Git. We use it, and by now so do most of you. Used conservatively, Git provides a good basis for information management (it keeps everything!).
But it is important to understand Git's limits. Without a live connection to the editors, merge tools etc that munge the files, Git is relegated to simply discovering what has changed in the filesystem, and wisely just stores new stuff, using content-based addressing to determine what is new.
Any further information we get from such a recording of novelty has to be derived. Diffs derive mechanical change information, and tree and file diffs are at the core of Git's facilities.
Language-aware analyses can derive change information co-aligned with program semantics.
How it works
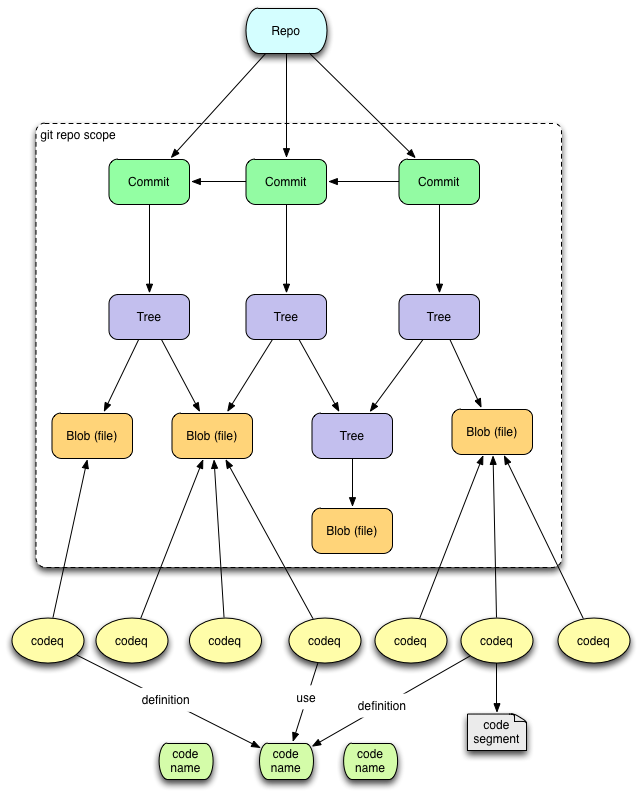
Git looks in directories and finds files, names them by the SHAs of their contents, and encodes their relationship to the enclosing tree by filename. During the import phase,
codeq pretty much transfers Git's model intact.
During the analysis phase,
codeq looks in files and finds code segments, names them by their SHAs, and encodes their relationship to the enclosing file by line+column location. It further associates them with programmatic names and semantics (e.g. definition, or usage), if possible. We call this semantic segment a
codeq.
Thus, one way to understand
codeq is as an extension of the git model and tree down to a finer granularity, aligned to program semantics.
codeq Model
In Git, every repo is an island. When trying to understand the interactions across your entire program, including the many libraries it uses, each with their own Git repo, it becomes useful to combine repo information in a single database. The beauty of content-based addressing and globally unique namespacing (as done by e.g. Java and Clojure) is that such merging is conflict-free. So,
codeq supports the importation of multiple repos into the same database and keeps them sorted, superimposing a level above the Git model.
In Detail
Now we can consider a particular scenario - a programmer edits a file, changing one function definition and inserting another.
From the Git perspective, the two files are different blobs, with different SHAs, in different trees under the same name. Anything else it tells you about what has changed is done via dynamic diffing, and is usually expressed in terms of lines and blocks of text.
Since we know (some of) these files are programs, and they are stored immutably, it seems worthwhile to perform a one-time analysis in order to track change more finely.
codeq will break down the top level of the file into the corresponding program-language units (e.g. for Clojure, mostly function-defining forms). It gives each a SHA (if the block of code has never been seen before). It will then look inside and try to determine what the code is about (in context - since the same code can appear e.g. in different namespaces and thus name different things). The 'meaning' is normally some reference to a namespaced program identity, and for some purpose (definition, use). So a
codeq encodes the location of a code segment in a file, and its semantics.
File edit:
After the edit, the analysis finds the identical first 2 segments in the same place in the new file, a new segment following, and then the old 3rd segment in a new location. The file ends with a new code segment, but is 'about' the same thing as the prior 4th segment. As time goes by we can get timelines for program constructs that are independent of the timelines of the files that contain them, and more closely aligned with our work (what's the history of this function definition?)
This importation and analysis is not a one-shot thing. You continue to use Git normally. You can go back later and import your newer changes from Git, or perform new or enhanced analyses. Due to the first-class nature of Datomic transactions, the
codeq database knows what has happened to it, what has been imported, what analyses have been run, what schemas have been installed etc.
Put on a happy interface
Git has a powerful engine - durable persistent data structures with structural sharing and some fast C code that manipulates them. Unfortunately, it is hidden behind a plethora of command line utilities each of which has a boatload of options and a variety of outputs - let's have a parsing party!
If only we had some declarative query technology with elegant support for recursion, we could turn all this tree walking into a piece of cake. Wait! - we can fight 1970's technology with... more 1970's technology - Datalog
(def rules
'[[(node-files ?n ?f) [?n :node/object ?f] [?f :git/type :blob]]
[(node-files ?n ?f) [?n :node/object ?t] [?t :git/type :tree]
[?t :tree/nodes ?n2] (node-files ?n2 ?f)]
[(object-nodes ?o ?n) [?n :node/object ?o]]
[(object-nodes ?o ?n) [?n2 :node/object ?o] [?t :tree/nodes ?n2] (object-nodes ?t ?n)]
[(commit-files ?c ?f) [?c :commit/tree ?root] (node-files ?root ?f)]
[(commit-codeqs ?c ?cq) (commit-files ?c ?f) [?cq :codeq/file ?f]]
[(file-commits ?f ?c) (object-nodes ?f ?n) [?c :commit/tree ?n]]
[(codeq-commits ?cq ?c) [?cq :codeq/file ?f] (file-commits ?f ?c)]])
You can follow along with
the schema, but suffice to say, that is all the code you need to:
- Find all the files referenced by a commit
- Find all the codeqs referenced by a commit
- Find all the commits including a file
- Find all the commits including a codeq
This query uses those rules to find all of the different definitions of the function
datomic.codeq.core/commit, and when they were first defined:
(d/q '[:find ?src (min ?date)
:in $ % ?name
:where
[?n :code/name ?name]
[?cq :clj/def ?n]
[?cq :codeq/code ?cs]
[?cs :code/text ?src]
[?cq :codeq/file ?f]
(file-commits ?f ?c)
(?c :commit/authoredAt ?date)]
db rules "datomic.codeq.core/commit")
If you don't know Datalog, it's worth the
11 minutes it will take you to learn it.
I hope this gives you a sense of the motivation for
codeq, and some excitement for trying it out. It's still early days, and we are definitely looking for help in enhancing the analysis, integrating with tools, supporting other languages etc.
Have fun!
Rich